如何处理更加复杂的 HTML 模板
我想编写更复杂的 HTML 模板
根据我们现在编写完成的状态来看,最多只支持标签名称、属性和文本内容。 因此,我希望能够在 template 中编写更加复杂的 HTML 模板。
具体来看,就是我希望能够完成下面这种模板的编译。
const app = createApp({
template: `
<div class="container" style="text-align: center">
<h2>Hello, chibivue!</h2>
<img
width="150px"
src="https://upload.wikimedia.org/wikipedia/commons/thumb/9/95/Vue.js_Logo_2.svg/1200px-Vue.js_Logo_2.svg.png"
alt="Vue.js Logo"
/>
<p><b>chibivue</b> is the minimal Vue.js</p>
<style>
.container {
height: 100vh;
padding: 16px;
background-color: #becdbe;
color: #2c3e50;
}
</style>
</div>
`,
})
app.mount('#app')但是,如果仅仅使用正则表达式来实现这么复杂的解析是非常非常困难的。
所以我现在将开始认真的实现解析器。
AST 简介
在实现完整的编译器之前,我们先了解一下需要用到的称为 AST 的“东西”。
AST 全称为 Abstract Syntax Tree(抽象语法树),顾名思义,它是以树状的形式表现某种编程语言的语法结构。 这个概念不仅仅是在 Vue.js 中有使用,而是在实现各种编译器时都会出现的概念。 在许多情况下(在语言处理系统中),“解析” 就是指将某个语言的语法转换为对应的 AST 表达式。
每种语言都定义了自己的 AST。
例如,我们熟悉的 JavaScript 是使用名为 estree 的 AST 来表达的,并且内部源代码中的字符串是根据此定义进行解析的。
我尝试过用酷一点的方式来对它进行解释,但是在我看来,这只是让我们迄今为止实现的解析函数的返回值具有更正式的类型定义。
目前我们的 parse 函数的返回值定义是这样的:
type ParseResult = {
tag: string
props: Record<string, string>
textContent: string
}我们可以试着将其扩展为更加复杂的表达式的定义。
新たに ~/packages/compiler-core/ast.ts を作成します。
少し長いので、コード中に説明を書きながら説明を進めます。
我们新建一个文件 —— ~/packages/compiler-core/ast.ts。
因为这部分内容有点长,所以我会一遍编写代码一边对代码进行说明。
// 这里表示 Node 节点的种类
// 需要注意的是,这里所说的 Node 并不是 HTML 的 Node,而是当前这个模板编译器的处理粒度。
// 因此,不仅是 Element 和 Text,属性也被视为一个 Node。
// 这也是按照 Vue.js 源码中设计的粒度来实现的,对今后划分目录和实现代码等非常有用。
export const enum NodeTypes {
ELEMENT,
TEXT,
ATTRIBUTE,
}
// 所有 Node 都有 type 和 loc 属性。
// loc 是指 location,是用来记录该 Node 位于源代码 (模板字符串) 的哪个位置。
// (在第几行的第几个字符等)
export interface Node {
type: NodeTypes
loc: SourceLocation
}
// Element 对应的 Node 定义。
export interface ElementNode extends Node {
type: NodeTypes.ELEMENT
tag: string // eg. "div"
props: Array<AttributeNode> // eg. { name: "class", value: { content: "container" } }
children: TemplateChildNode[]
isSelfClosing: boolean // eg. <img /> -> true
}
// ElementNode 的属性。
// 可以用普通的 Record<string, string> 来表示
// 模拟 Vue 中的 name(string) 和 value(TextNode) 两个属性
export interface AttributeNode extends Node {
type: NodeTypes.ATTRIBUTE
name: string
value: TextNode | undefined
}
export type TemplateChildNode = ElementNode | TextNode
export interface TextNode extends Node {
type: NodeTypes.TEXT
content: string
}
// 这里定义 Node 中的 loc(location) 属性的类型
// start, end 中包含位置信息。
// source 中包含实际代码 (源代码字符串)。
export interface SourceLocation {
start: Position
end: Position
source: string
}
export interface Position {
offset: number // from start of file
line: number
column: number
}这就是我们这次要处理的 AST。
我们现在要实现的 parse 函数就是要完成将 template 模板字符串转换为这种格式的 AST。
完整的解析器实现
WARNING
2023 年 11 月下旬, vuejs/core 进行了 用于改善性能的大规模重写。
它们于 2023 年 12 月底作为 Vue 3.4。需要注意的是,这本在线书籍是基于重写之前的实现来编写的。 我们也会在合适的时候对这本书进行修改。
我们会在 ~/packages/compiler-core/parse.ts 中实现这个完整的解析器。
即使现在你还没有做什么准备,觉得有些困难,但实际上不需要太过担心。我们所要做的基本上就是读取字符串内容通过不同的判断条件分支,然后循环执行生成 AST。 虽然源代码会比较多,但是我认为在代码中给出注释来解释会更加容易理解,所以这部分内容我会按照这种方式进行。 所以请仔细阅读源代码来详细了解如何实现。
本格的と言ってもあまり身構えなくて大丈夫です。やっていることは基本的に文字列を読み進めながら分岐やループを活用して AST を生成しているだけです。
ソースコードが少し多くなりますが、説明もコードベースの方が分かりやすいと思うのでそう進めていきます。
細かい部分はぜひソースコードを読んで把握してみてください。
删除之前实现的 baseParse 函数中的内容,并将返回值类型更改为以下格式。
import { TemplateChildNode } from './ast'
export const baseParse = (
content: string,
): { children: TemplateChildNode[] } => {
// TODO:
return { children: [] }
}Context 上下文
首先,我们将实现解析过程中会使用的状态数据(上下文)。 将其名称为 ParserContext 并且在这里收集解析过程中所需要的各种信息。 我觉得最终它还会保留例如解析器配置选项这类参数或者属性。
export interface ParserContext {
// 原始模板字符串
readonly originalSource: string
source: string
// 解析器当前读取到的位置
offset: number
line: number
column: number
}
function createParserContext(content: string): ParserContext {
return {
originalSource: content,
source: content,
column: 1,
line: 1,
offset: 0,
}
}
export const baseParse = (
content: string,
): { children: TemplateChildNode[] } => {
const context = createParserContext(content) // 生成 context 上下文对象
// TODO:
return { children: [] }
}parseChildren 子节点解析
按照 (parseChildren) -> (parseElement 或者 parseText) 这样的解析顺序。
代码会有点儿长,我们从 parseChildren 的实现开始讲起,会在代码中通过注释的方式给出解析说明。
export const baseParse = (
content: string,
): { children: TemplateChildNode[] } => {
const context = createParserContext(content)
const children = parseChildren(context, []) // 解析子节点
return { children: children }
}
function parseChildren(
context: ParserContext,
// 由于 HTML 具有递归结构,因此我们将祖先元素保留为栈结构,并在每次发现嵌套子元素时将其推进栈顶
// 当找到结束标签时,parseChildren 会结束并从其父元素中弹出该元素。
ancestors: ElementNode[],
): TemplateChildNode[] {
const nodes: TemplateChildNode[] = []
while (!isEnd(context, ancestors)) {
const s = context.source
let node: TemplateChildNode | undefined = undefined
if (s[0] === '<') {
// 如果 s 以 “<” 开头,并且下一个字符是字母,则作为元素进行解析。
if (/[a-z]/i.test(s[1])) {
node = parseElement(context, ancestors) // TODO: 稍后开始实现。
}
}
if (!node) {
// 如果不符合上述条件,则作为 TextNode 进行解析。
node = parseText(context) // TODO: 稍后开始实现。
}
pushNode(nodes, node)
}
return nodes
}
// 用于判定 (元素解析结束),即通过循环判断 ancestors 元素数组中是否存在这个结束标签对应的开始标签
function isEnd(context: ParserContext, ancestors: ElementNode[]): boolean {
const s = context.source
// 如果s以 “</” 开头,并且之后的标签名与 ancestors 中的某个标签名对应,则确定存在结束标签(即在此结束 parseChildren)
if (startsWith(s, '</')) {
for (let i = ancestors.length - 1; i >= 0; --i) {
if (startsWithEndTagOpen(s, ancestors[i].tag)) {
return true
}
}
}
return !s
}
function startsWith(source: string, searchString: string): boolean {
return source.startsWith(searchString)
}
function pushNode(nodes: TemplateChildNode[], node: TemplateChildNode): void {
// 如果连续的 Node 类型都是 TEXT 的话,就把他们组合起来
if (node.type === NodeTypes.TEXT) {
const prev = last(nodes)
if (prev && prev.type === NodeTypes.TEXT) {
prev.content += node.content
return
}
}
nodes.push(node)
}
function last<T>(xs: T[]): T | undefined {
return xs[xs.length - 1]
}
function startsWithEndTagOpen(source: string, tag: string): boolean {
return (
startsWith(source, '</') &&
source.slice(2, 2 + tag.length).toLowerCase() === tag.toLowerCase() &&
/[\t\r\n\f />]/.test(source[2 + tag.length] || '>')
)
}接下来,就是实现 parseElement 和 parseText 函数了。
关于 isEnd 循环
isEnd 使用循环判断 startsWithEndTagOpen 检查 ancestors 祖先数组中的每个元素,以查看字符串 s 是否是以该元素对应的结束标记作为开头的字符串。
function isEnd(context: ParserContext, ancestors: ElementNode[]): boolean {
const s = context.source
// 如果s以 “</” 开头,并且之后的标签名与 ancestors 中的某个标签名对应,则确定存在结束标签(即在此结束 parseChildren)
if (startsWith(s, '</')) {
for (let i = ancestors.length - 1; i >= 0; --i) {
if (startsWithEndTagOpen(s, ancestors[i].tag)) {
return true
}
}
}
return !s
}然而,实际上如果我们想检查字符串 s 是否是一个以结束标签开头的字符串,你只需要检查祖先数组的 最后一个元素。 所以 Vue.js 3.4 的解析器部分删除(重写内容中)了这段代码。 但即使您在 3.4 的重写之前将 Vue 3.3 中的代码修改为仅检查祖先数组的最后一个元素,所有正常测试也都会通过。
parseText 文本解析
现在我们先从最简单的 parseText 函数开始。
这部分可能也有点儿长,因为它还实现了一些除了提供给 parseText 函数之外还会提供给其他函数使用的工具函数。
function parseText(context: ParserContext): TextNode {
// 直到读取到 “<” (无论是开始标记还是结束标记)时,根据已读取了多少个字符来计算文本数据的结束点的索引。
const endToken = '<'
let endIndex = context.source.length
const index = context.source.indexOf(endToken, 1)
if (index !== -1 && endIndex > index) {
endIndex = index
}
const start = getCursor(context) // 这是给 loc 用的
// 根据 endIndex 的信息解析 Text 数据。
const content = parseTextData(context, endIndex)
return {
type: NodeTypes.TEXT,
content,
loc: getSelection(context, start),
}
}
// 根据 content 和 length 提取 text 文本
function parseTextData(context: ParserContext, length: number): string {
const rawText = context.source.slice(0, length)
advanceBy(context, length)
return rawText
}
// -------------------- 下面的是工具函数部分。(也会提供给后面的 parseElement 使用) --------------------
function advanceBy(context: ParserContext, numberOfCharacters: number): void {
const { source } = context
advancePositionWithMutation(context, source, numberOfCharacters)
context.source = source.slice(numberOfCharacters)
}
// 虽然有点长,但是做的事情很单纯,就是进行 pos 的计算。
// 它破坏性地更新参数中接收到的 pos 对象。
function advancePositionWithMutation(
pos: Position,
source: string,
numberOfCharacters: number = source.length,
): Position {
let linesCount = 0
let lastNewLinePos = -1
for (let i = 0; i < numberOfCharacters; i++) {
if (source.charCodeAt(i) === 10 /* newline char code */) {
linesCount++
lastNewLinePos = i
}
}
pos.offset += numberOfCharacters
pos.line += linesCount
pos.column =
lastNewLinePos === -1
? pos.column + numberOfCharacters
: numberOfCharacters - lastNewLinePos
return pos
}
function getCursor(context: ParserContext): Position {
const { column, line, offset } = context
return { column, line, offset }
}
function getSelection(
context: ParserContext,
start: Position,
end?: Position,
): SourceLocation {
end = end || getCursor(context)
return {
start,
end,
source: context.originalSource.slice(start.offset, end.offset),
}
}parseElement
接下来就是元素的解析。 元素解析主要包括起始标签解析、子节点解析和结束标签解析,起始标签解析又分为标签名和属性。
首先,我们创建一个解析方法来解析前半部分内容,也就是开始标签、子节点和结束标签。
const enum TagType {
Start,
End,
}
function parseElement(
context: ParserContext,
ancestors: ElementNode[],
): ElementNode | undefined {
// 开始标签
const element = parseTag(context, TagType.Start) // TODO:
// 如果是像 <img/> 这样的自闭合(self closing)元素,则直接在这里结束。(因为既没有子元素也没有结束标签)
if (element.isSelfClosing) {
return element
}
// 子元素.
ancestors.push(element)
const children = parseChildren(context, ancestors)
ancestors.pop()
element.children = children
// 结束标签.
if (startsWithEndTagOpen(context.source, element.tag)) {
parseTag(context, TagType.End) // TODO:
}
return element
}我觉得这部分并不是特别困难。
但是要注意 parseChildren 是递归调用的(因为 parseElement 就是由 parseChildren 调用的)。
在 parseChildren 前后都要进行 ancestors 元素数组作为栈的操作(译者注:即提前栈顶插入当前元素,然后开始解析子元素,最后弹出栈顶元素)。
然后我们开始实现 parseTag 函数。
function parseTag(context: ParserContext, type: TagType): ElementNode {
// 标签开始部分
const start = getCursor(context)
const match = /^<\/?([a-z][^\t\r\n\f />]*)/i.exec(context.source)!
const tag = match[1]
advanceBy(context, match[0].length)
advanceSpaces(context)
// 属性解析.
let props = parseAttributes(context, type)
// 是否自闭合标签
let isSelfClosing = false
// 在读取到属性的时候,如果下一个字符是 “>”,则为 SelfClosing 自闭合标签
isSelfClosing = startsWith(context.source, '/>')
advanceBy(context, isSelfClosing ? 2 : 1)
return {
type: NodeTypes.ELEMENT,
tag,
props,
children: [],
isSelfClosing,
loc: getSelection(context, start),
}
}
// 整个属性内容体 (包含多个属性) 的解析
// eg. `id="app" class="container" style="color: red"`
function parseAttributes(
context: ParserContext,
type: TagType,
): AttributeNode[] {
const props = []
const attributeNames = new Set<string>()
// 继续遍历,直到开始标签结束(也就是 “>” 或者 “/>”)
while (
context.source.length > 0 &&
!startsWith(context.source, '>') &&
!startsWith(context.source, '/>')
) {
const attr = parseAttribute(context, attributeNames)
if (type === TagType.Start) {
props.push(attr)
}
advanceSpaces(context) // 跳过空格
}
return props
}
type AttributeValue =
| {
content: string
loc: SourceLocation
}
| undefined
// 单个属性串的解析
// eg. `id="app"`
function parseAttribute(
context: ParserContext,
nameSet: Set<string>,
): AttributeNode {
// 属性名.
const start = getCursor(context)
const match = /^[^\t\r\n\f />][^\t\r\n\f />=]*/.exec(context.source)!
const name = match[0]
nameSet.add(name)
advanceBy(context, name.length)
// 属性值
let value: AttributeValue = undefined
if (/^[\t\r\n\f ]*=/.test(context.source)) {
advanceSpaces(context)
advanceBy(context, 1)
advanceSpaces(context)
value = parseAttributeValue(context)
}
const loc = getSelection(context, start)
return {
type: NodeTypes.ATTRIBUTE,
name,
value: value && {
type: NodeTypes.TEXT,
content: value.content,
loc: value.loc,
},
loc,
}
}
// 属性值 value 的解析
// value 的引号既可以单引号也可以双引号。
// 这也只是尽力取出被引号包围的 value。
function parseAttributeValue(context: ParserContext): AttributeValue {
const start = getCursor(context)
let content: string
const quote = context.source[0]
const isQuoted = quote === `"` || quote === `'`
if (isQuoted) {
// 引号内的值
advanceBy(context, 1)
const endIndex = context.source.indexOf(quote)
if (endIndex === -1) {
content = parseTextData(context, context.source.length)
} else {
content = parseTextData(context, endIndex)
advanceBy(context, 1)
}
} else {
// 没有在引号中的值
const match = /^[^\t\r\n\f >]+/.exec(context.source)
if (!match) {
return undefined
}
content = parseTextData(context, match[0].length)
}
return { content, loc: getSelection(context, start) }
}完整的解析器实现之后
这里我写了很多代码(大概有 300 多行)。 但我任务比起用语言来解释,阅读这部分的代码实现反而更加容易理解,所以请大家多阅读几次。 代码虽然很多,但是基本上都是遍历字符串进行解析,并没有什么特别难的技巧,都是基础知识。
现在我们应该能够生成 AST 了,我们先确定一下是否能够正常解析模板内容。
但是,由于我们还没有实现 codegen 代码生成部分,所以这里先用 console 输出到浏览器控制台来进行检查。
const app = createApp({
template: `
<div class="container" style="text-align: center">
<h2>Hello, chibivue!</h2>
<img
width="150px"
src="https://upload.wikimedia.org/wikipedia/commons/thumb/9/95/Vue.js_Logo_2.svg/1200px-Vue.js_Logo_2.svg.png"
alt="Vue.js Logo"
/>
<p><b>chibivue</b> is the minimal Vue.js</p>
<style>
.container {
height: 100vh;
padding: 16px;
background-color: #becdbe;
color: #2c3e50;
}
</style>
</div>
`,
})
app.mount('#app')~/packages/compiler-core/compile.ts
export function baseCompile(template: string) {
const parseResult = baseParse(template.trim()) // 移除 template 头尾空格
console.log(
'🚀 ~ file: compile.ts:6 ~ baseCompile ~ parseResult:',
parseResult,
)
// TODO: codegen
// const code = generate(parseResult);
// return code;
return ''
}现在屏幕将会是空白的,我们检查一下控制台的输出。
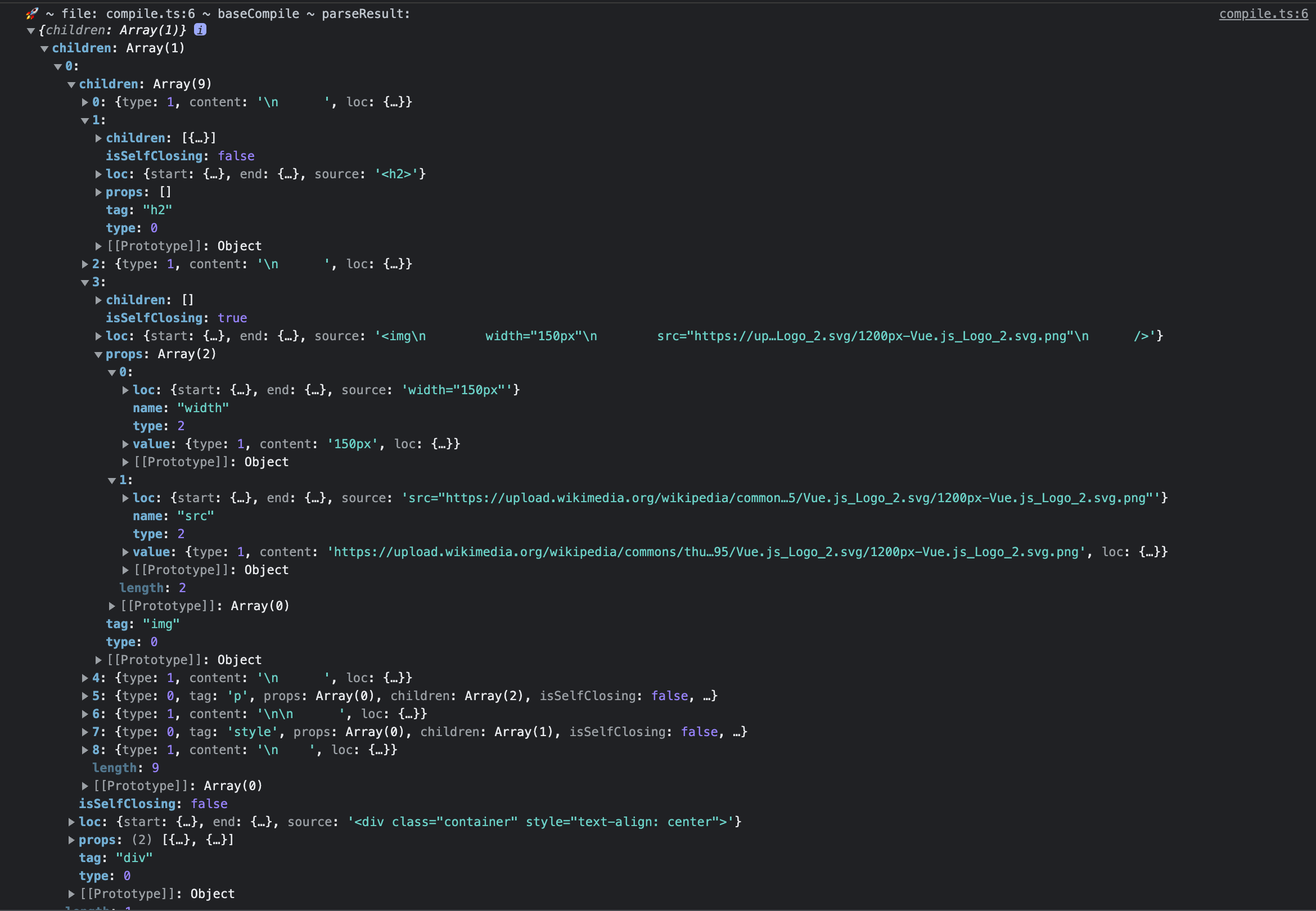
看起来我们做得不错。
现在,我们将根据此处生成的 AST 继续实现 codegen。
基于 AST 生成 render 渲染函数
现在我们已经实现了一个完整成熟的解析器,下一步就是创建一个适配它的代码生成器。 也就是说,目前还不需要太过复杂的实现。
首先我先展示一下编写的代码:
import { ElementNode, NodeTypes, TemplateChildNode, TextNode } from './ast'
export const generate = ({
children,
}: {
children: TemplateChildNode[]
}): string => {
return `return function render() {
const { h } = ChibiVue;
return ${genNode(children[0])};
}`
}
const genNode = (node: TemplateChildNode): string => {
switch (node.type) {
case NodeTypes.ELEMENT:
return genElement(node)
case NodeTypes.TEXT:
return genText(node)
default:
return ''
}
}
const genElement = (el: ElementNode): string => {
return `h("${el.tag}", {${el.props
.map(({ name, value }) => `${name}: "${value?.content}"`)
.join(', ')}}, [${el.children.map(it => genNode(it)).join(', ')}])`
}
const genText = (text: TextNode): string => {
return `\`${text.content}\``
}您可以自己编写一些可以与上述内容一起使用的东西。
现在让我们取消在模板解析器一章(上一章)中注释掉的部分,看看它实际上是如何工作的。
~/packages/compiler-core/compile.ts
export function baseCompile(template: string) {
const parseResult = baseParse(template.trim())
const code = generate(parseResult)
return code
}playground
import { createApp } from 'chibivue'
const app = createApp({
template: `
<div class="container" style="text-align: center">
<h2>Hello, chibivue!</h2>
<img
width="150px"
src="https://upload.wikimedia.org/wikipedia/commons/thumb/9/95/Vue.js_Logo_2.svg/1200px-Vue.js_Logo_2.svg.png"
alt="Vue.js Logo"
/>
<p><b>chibivue</b> is the minimal Vue.js</p>
<style>
.container {
height: 100vh;
padding: 16px;
background-color: #becdbe;
color: #2c3e50;
}
</style>
</div>
`,
})
app.mount('#app')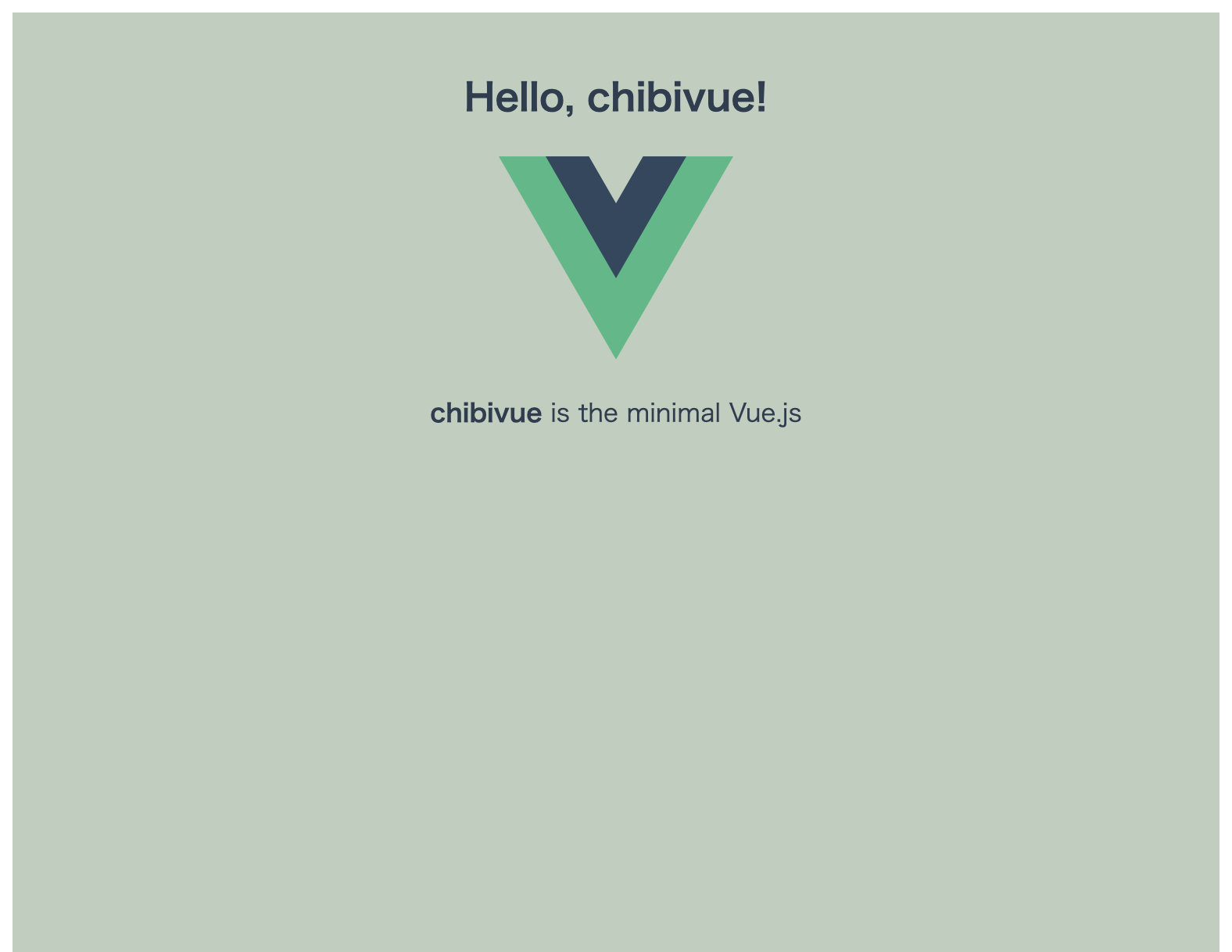
怎么样?看起来我们好像已经能很好的渲染内容了。
せっかくなので画面に動きをつけてみます。テンプレートへのバインディングは実装していないので、直接 DOM 操作します。 让我们在元素上添加一些响应事件。 由于我们还没有实现模板绑定,因此我们这里直接操作 DOM 元素。
export type ComponentOptions = {
// .
// .
// .
setup?: (
props: Record<string, any>,
ctx: { emit: (event: string, ...args: any[]) => void },
) => Function | void // 让它也允许没有返回
// .
// .
// .
}import { createApp } from 'chibivue'
const app = createApp({
setup() {
// 因为需要在挂载(mount)完成之后再进行 DOM 操作,所以这里通过 Promise.resolve 延迟进行事件绑定
Promise.resolve().then(() => {
const btn = document.getElementById('btn')
btn &&
btn.addEventListener('click', () => {
const h2 = document.getElementById('hello')
h2 && (h2.textContent += '!')
})
})
},
template: `
<div class="container" style="text-align: center">
<h2 id="hello">Hello, chibivue!</h2>
<img
width="150px"
src="https://upload.wikimedia.org/wikipedia/commons/thumb/9/95/Vue.js_Logo_2.svg/1200px-Vue.js_Logo_2.svg.png"
alt="Vue.js Logo"
/>
<p><b>chibivue</b> is the minimal Vue.js</p>
<button id="btn"> click me! </button>
<style>
.container {
height: 100vh;
padding: 16px;
background-color: #becdbe;
color: #2c3e50;
}
</style>
</div>
`,
})
app.mount('#app')现在再验证一下它是不是能够正常工作。
怎么样?虽然现在它的功能还比较少,但是我觉得它已经越来越接近 Vue 提供的 “开发者界面” 了。
当前源代码位于: chibivue (GitHub)